How To: Analyze and Plot Three Point Shooting Trends
Sravan January 31, 2024 [NBA] #shooting #3PT #win-loss #trends #tutorialThis tutorial goes through the process of generating figures in my Three Point Shooting Trends blog. Please read the blog first before continuing on to the tutorial. In this tutorial you will learn the following:
- Scrape league average stats for several seasons using
nba_api. - Plot using
plotninewhich is a Python port ofR'sggplot. This package is how I generate most of my visualizations. - Saving data in different formats including:
csv,parquet&feather. We'll go through pros and cons of each. - Processing data using
pandas
If you want to run the code yourself while reading the tutorial, you can find the notebook version of this tutorial on my github:
First, let's start by loading the basic packages required for this tutorial.
# for processing data
# for numerical operations on arrays
# gives up progress bar
# don't raise warnings when chaining pandas operations
= None
=
Plotting Basic 3 PT Year to Year Trends
Scraping the Data
Now, let's load the function required for scraping league average data.
= 2023
# the function requires season to be in the form "2023-24" instead of "2024"
= + +
# Get per game stats for a regular season
=
# Get data frames
=
# We don't need all columns, so we load only a subset
=
| TEAM_NAME | W | L | W_PCT | FG3M | FG3A | FG3_PCT | |
|---|---|---|---|---|---|---|---|
| 0 | Atlanta Hawks | 20 | 27 | 0.426 | 13.6 | 37.7 | 0.361 |
| 1 | Boston Celtics | 37 | 11 | 0.771 | 16.2 | 42.6 | 0.380 |
# Sum all the columns and append sum as a new row
=
| TEAM_NAME | W | L | W_PCT | FG3M | FG3A | FG3_PCT | |
|---|---|---|---|---|---|---|---|
| Total | Atlanta HawksBoston CelticsBrooklyn NetsCharlo... | 701 | 701 | 14.981 | 384.6 | 1049.6 | 10.997 |
# Average the makes and attempts for 30 teams
= /30
= /30
# Get the percentage by dividing makes column with attempts column
= /
# Rename the team_name column entry of total row to the season
= +1
# round the columns to three decimals
=
# get only the last row i.e. the total row
=
=
| TEAM_NAME | FG3M | FG3A | FG3_PCT | |
|---|---|---|---|---|
| Total | 2024 | 12.82 | 34.987 | 0.366 |
Now let's run the above code for the past 10 seasons
=
# the function requires season to be in the form "2023-24" instead of "2024"
= + +
# Get per game stats for a regular season
=
# Get data frames
=
# We don't need all columns, so we load only a subset
=
=
= /30
= /30
= /
= +1
=
=
=
=
80%|████████ | 8/10 [00:06<00:01, 1.14it/s]
100%|██████████| 10/10 [00:08<00:00, 1.17it/s]
# rebane team name column to season
=
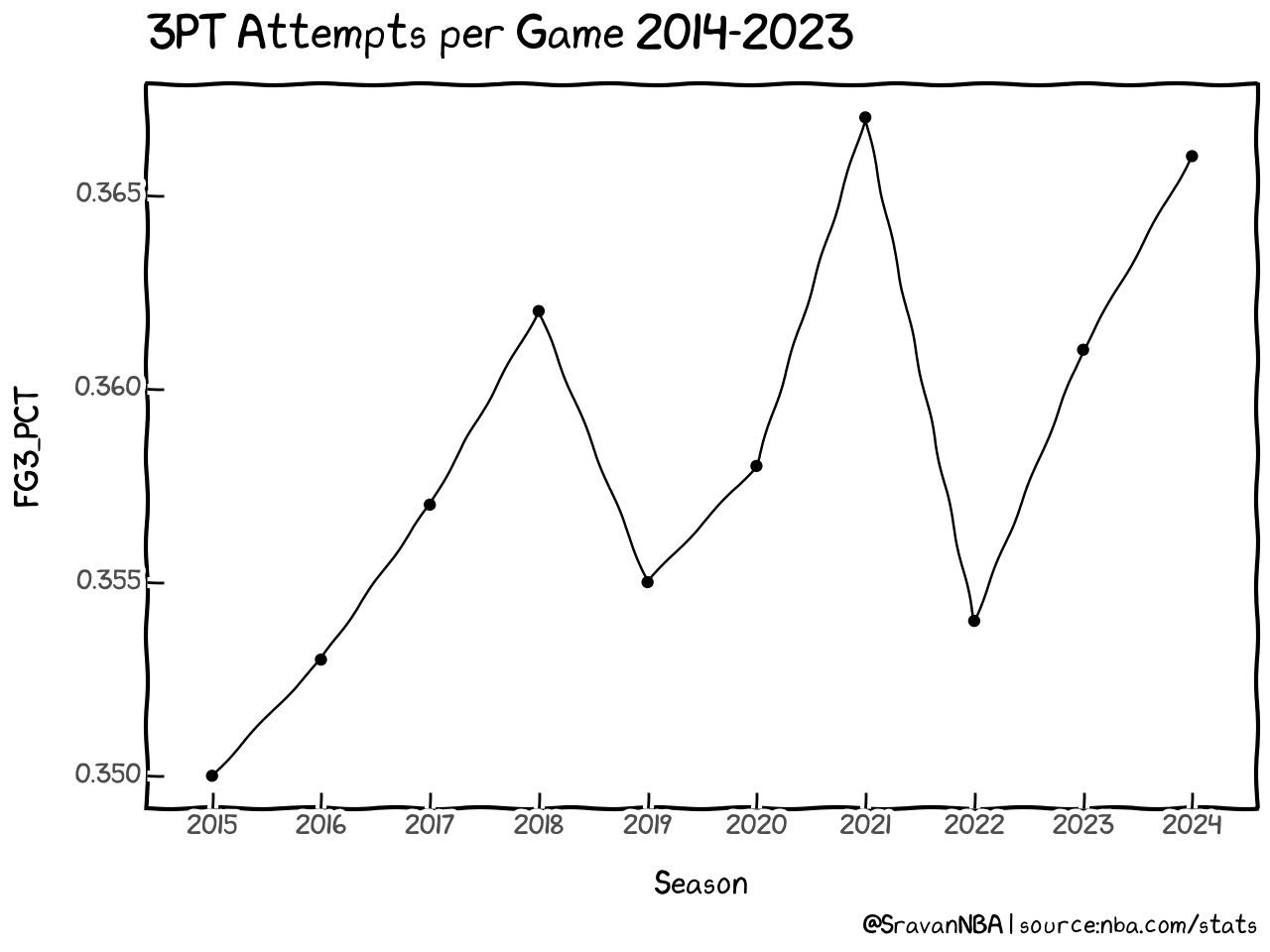
| Season | FG3M | FG3A | FG3_PCT | |
|---|---|---|---|---|
| 0 | 2015 | 7.850 | 22.410 | 0.350 |
| 1 | 2016 | 8.507 | 24.083 | 0.353 |
| 2 | 2017 | 9.650 | 27.003 | 0.357 |
| 3 | 2018 | 10.487 | 28.997 | 0.362 |
| 4 | 2019 | 11.360 | 32.007 | 0.355 |
| 5 | 2020 | 12.193 | 34.103 | 0.358 |
| 6 | 2021 | 12.707 | 34.637 | 0.367 |
| 7 | 2022 | 12.440 | 35.180 | 0.354 |
| 8 | 2023 | 12.340 | 34.207 | 0.361 |
| 9 | 2024 | 12.820 | 34.987 | 0.366 |
Plotting the Data using Plotnine
Now that we have the data, let's plot it. We'll do it using plotnine package. I recommend reading the documentation and going through the tutorials there.
Let's load the modules from plotnine, we'll use in plotting:
=
# draw the plot
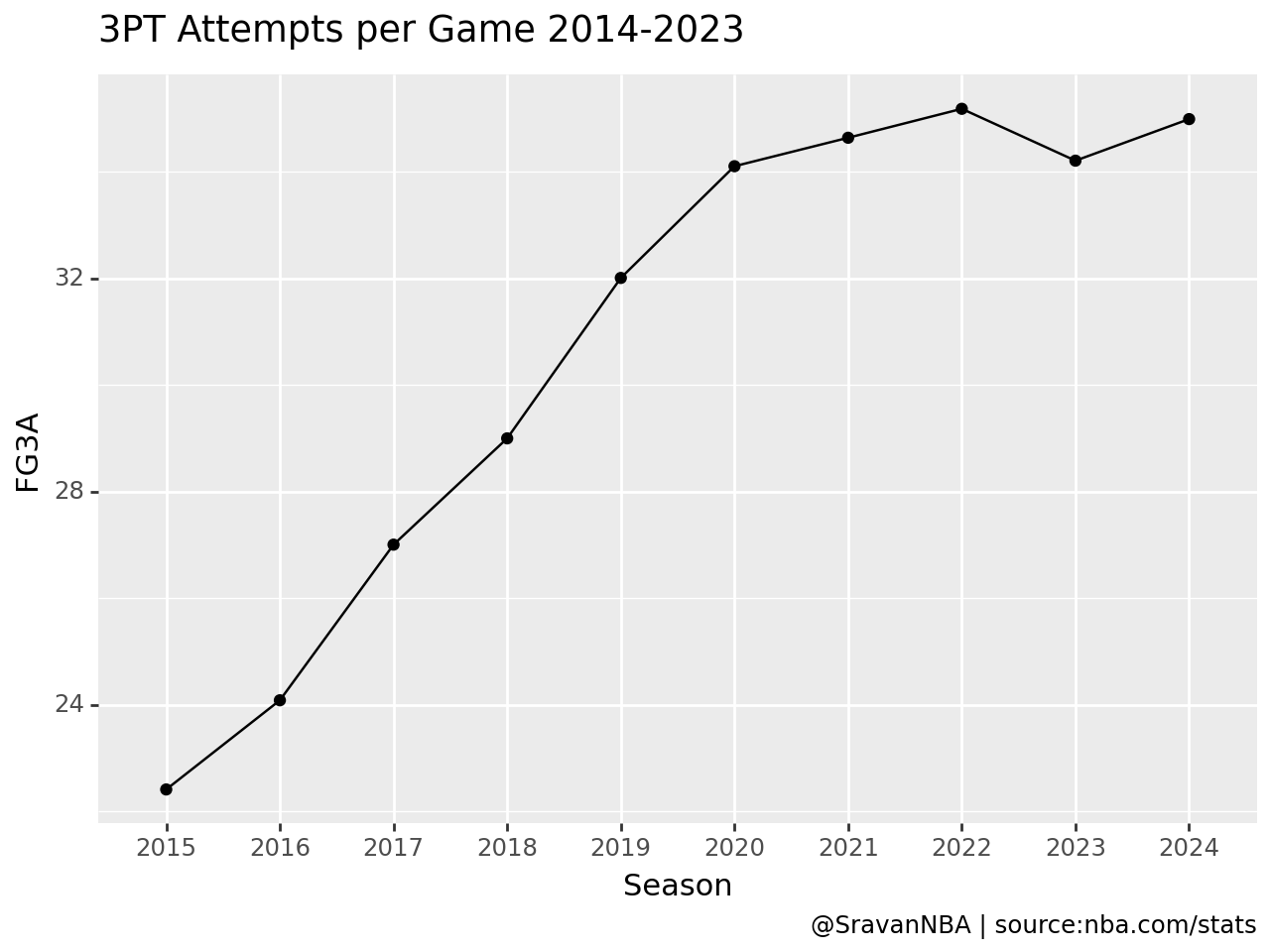
Wow, that was easy. The default plot here is much better formatted compared to a default matplotlib plot. This is what makes using plotnine fun and easy. We need to just worry about the data and then plotnine takes care about the formatting.
Now, lets make the plot even better looking by adding a theme. We need to import some things again from plotnine
We are going to be using the xkcd theme. For a list of available themes refer to plotnine themes documentation. Let's define the theme now:
=
I want to slightly modify the theme by making the title bold and increase the title font size to 16. That can be done by updating the theme like so:
+=
Now, we add the theme to the previous plot by just adding this line to the code + theme_idv
=
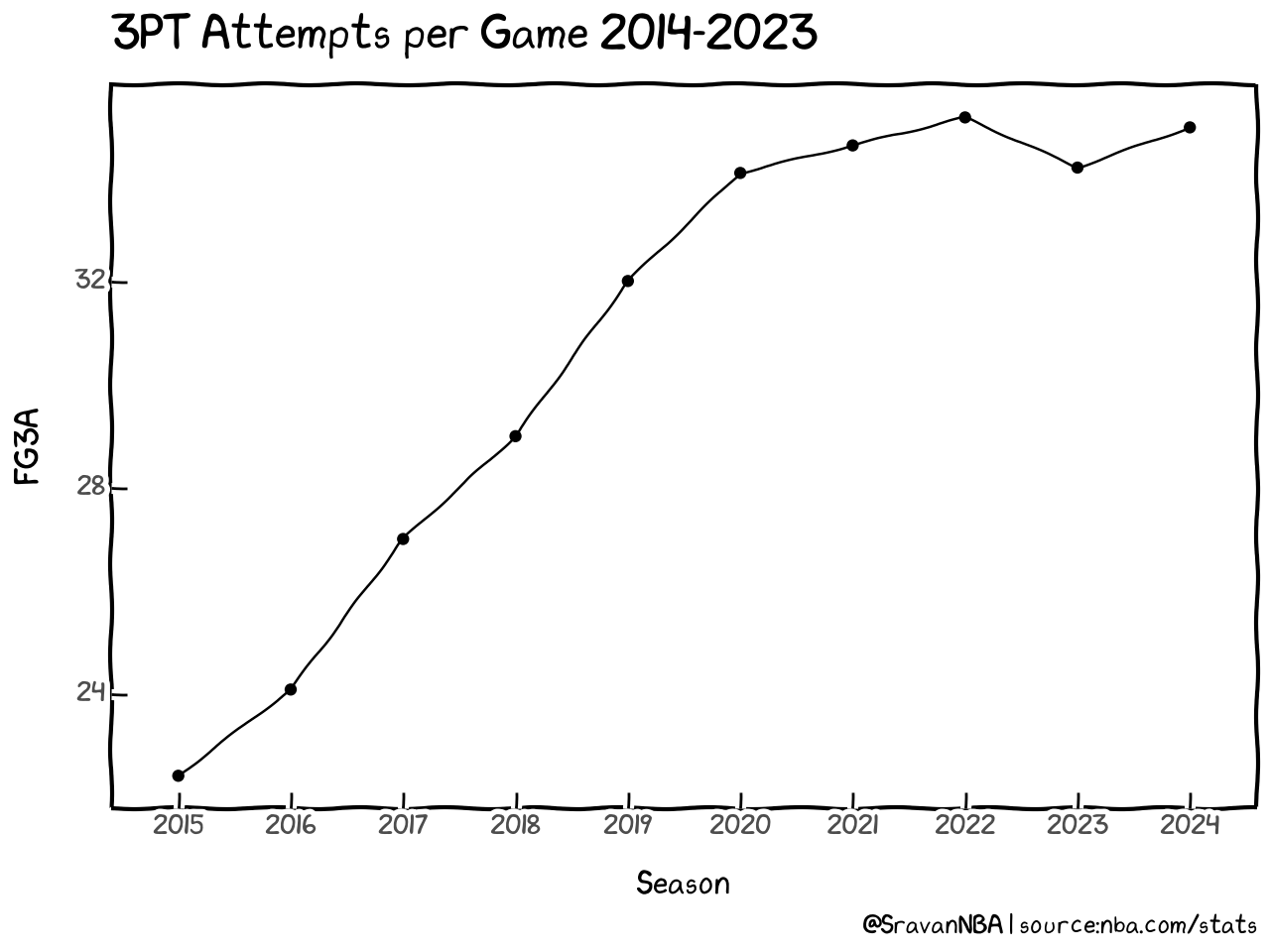
Wasn't that easy? Now the graph with xkcd looks much better than the vanilla theme we saw before. Similarly we can generate plot for 3PT Makes by just changing y="FGM" in the code. For generating 3PT percentage trends, we set y="FG3_PCT". Once you start getting used to plotnine, visualizing data will become much easier.
=
3FG% vs Wins Year to Year when Team 3P% > Opponent 3P% + 5%
Scraping Data and saving them in different file formats
Now, let's load the function required for boxscores, which are required to get individual game 3FG% and whether a team has won or not
=
# api call for getting the data
=
=
# define the file name string
= + + + +
pandas offers us several ways of saving dataframes. The most commonly used one is to_csv() which saves the data in a csv format. csv
I want to introduce you to other formats of storing data including parquet and feather.
New, let's try to evaluate how long it takes to save the file by using timeit magic function. Read more about jupyter/IPython built-in magic commands here.
%%
32.8 ms ± 2.5 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%
19.3 ms ± 1.31 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%
10.3 ms ± 1.83 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
Time taken to save: feather <parquet < csv
Let's look at the file sizes
=
= >> 10
355 kB
=
= >> 10
88 kB
=
= >> 10
256 kB
So,File size: parquet < feather < csv
I personally use parquet files over csv for the below reasons:
Parquet Files
- why not csv
- not compressed, can take too much space
- doesn't save
dtypes, pandas has to inferdtypesafter reading thecsv. It isn't reliable and sometimes you have to setdtypesmanually
- What is parquet
Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk.
- why parquet
- compressed automatically
- saves dtypes
- faster to write and load
- disadvantages
- you can't read the file visually, like you can a
csv - No proper/popular GUI tool to visualize
csvfiles like Microsoft Excel or Google Sheets
- you can't read the file visually, like you can a
Now let's back to scraping the data:
First we save the data in parquet format for all 10 seasons
= 2014
= 2024
=
=
=
100%|██████████| 10/10 [00:11<00:00, 1.17s/it]
Processing Data
Let's load data for a season
= 2023
=
| SEASON_ID | TEAM_ID | TEAM_ABBREVIATION | TEAM_NAME | GAME_ID | GAME_DATE | MATCHUP | WL | MIN | FGM | ... | DREB | REB | AST | STL | BLK | TOV | PF | PTS | PLUS_MINUS | VIDEO_AVAILABLE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 22023 | 1610612747 | LAL | Los Angeles Lakers | 0022300061 | 2023-10-24 | LAL @ DEN | L | 240 | 41 | ... | 31 | 44 | 23 | 5 | 4 | 12 | 18 | 107 | -12 | 1 |
| 1 | 22023 | 1610612743 | DEN | Denver Nuggets | 0022300061 | 2023-10-24 | DEN vs. LAL | W | 240 | 48 | ... | 33 | 42 | 29 | 9 | 6 | 12 | 15 | 119 | 12 | 1 |
2 rows × 29 columns
Each row, only has that team's data but we need both teams data in a single row to compare 3PT shooting between two teams. To have data for both teams in the same row, we follow same steps as in the previous tutorial.
=
=
=
=
= +
= +
=
=
=
= +
= +
=
=
| GAME_ID | TEAM_NAME1 | FG3A1 | FG3M1 | FG3_PCT1 | PLUS_MINUS1 | TEAM_NAME2 | FG3A2 | FG3M2 | FG3_PCT2 | PLUS_MINUS2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0022300001 | Indiana Pacers | 31 | 15 | 0.484 | 5 | Cleveland Cavaliers | 28 | 8 | 0.286 | -5 |
| 1 | 0022300001 | Cleveland Cavaliers | 28 | 8 | 0.286 | -5 | Indiana Pacers | 31 | 15 | 0.484 | 5 |
=
# 3 Point shooting of team > 5% of opponent
= >
# Define Win and Loss
= > 0
= < 0
# Wins when 3FG% of team > 3FG% of opponent + 5%
= &
= &
# Aggregate all values together for a team
= \
=
=
# Sum values from all teams to total row for the season
=
=
= +1
# get the total row out as a dataframe
=
Now, we have to run the same process for all 10 seasons
=
=
=
=
=
=
= +
= +
=
=
=
= +
= +
=
=
=
= >
= > 0
= < 0
= &
= &
= \
=
=
=
=
= +1
=
=
=
=
Here is the dataframe which we will plot next
| Season | Win_More_3PT_PCT | Loss_More_3PT_PCT | Win_PCT | |
|---|---|---|---|---|
| 0 | 2015 | 655 | 252 | 0.722 |
| 1 | 2016 | 656 | 222 | 0.747 |
| 2 | 2017 | 693 | 195 | 0.780 |
| 3 | 2018 | 635 | 210 | 0.751 |
| 4 | 2019 | 661 | 189 | 0.778 |
| 5 | 2020 | 565 | 171 | 0.768 |
| 6 | 2021 | 600 | 143 | 0.808 |
| 7 | 2022 | 655 | 166 | 0.798 |
| 8 | 2023 | 635 | 163 | 0.796 |
| 9 | 2024 | 351 | 98 | 0.782 |
=
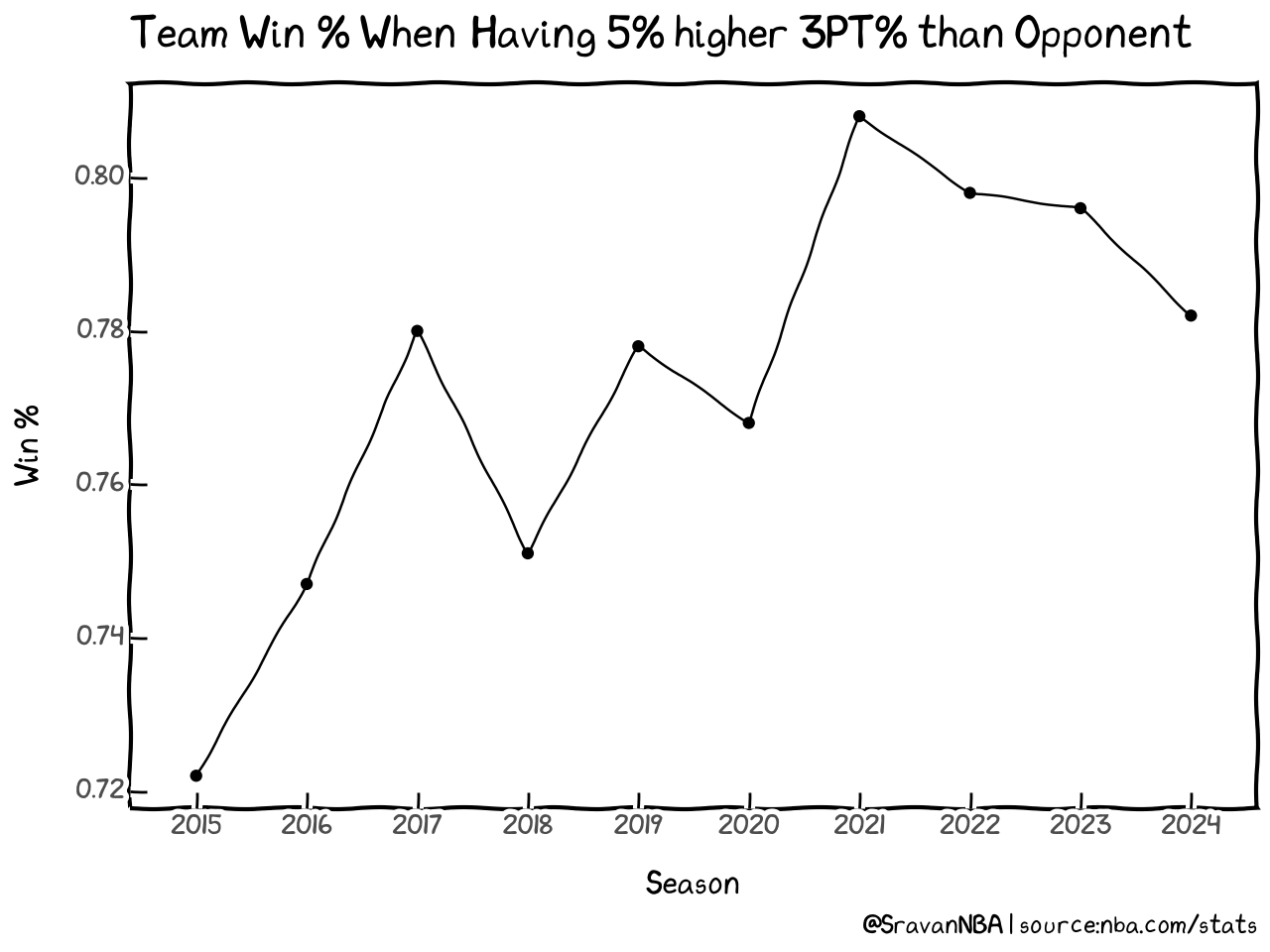
Now, lets format the Y axis to show data in percentage instead of fraction
=
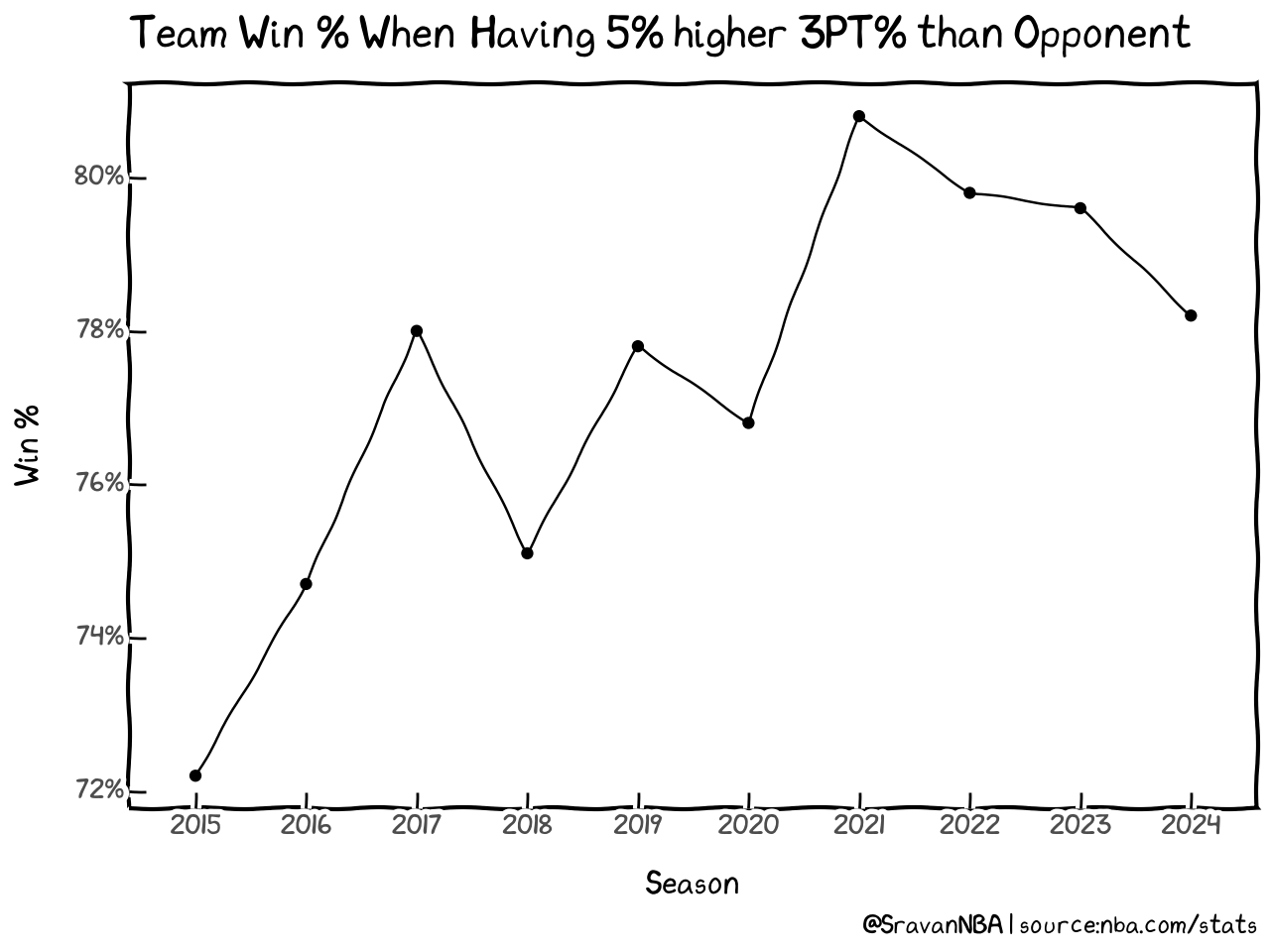
Finally you can save the figure using the save command
c:\Users\pansr\AppData\Local\pypoetry\Cache\virtualenvs\nba-ub9Z_EQq-py3.11\Lib\site-packages\plotnine\ggplot.py:587: PlotnineWarning: Saving 6.2 x 4.8 in image.
c:\Users\pansr\AppData\Local\pypoetry\Cache\virtualenvs\nba-ub9Z_EQq-py3.11\Lib\site-packages\plotnine\ggplot.py:588: PlotnineWarning: Filename: FG3PCT_Wins_seasons.png
Reminder
You can find the notebook version of this tutorial on my github: https://github.com/sravanpannala/NBA-Tutorials/blob/main/three_pt_shooting_trends/plotting_three_pt_shooting_trends.ipynb